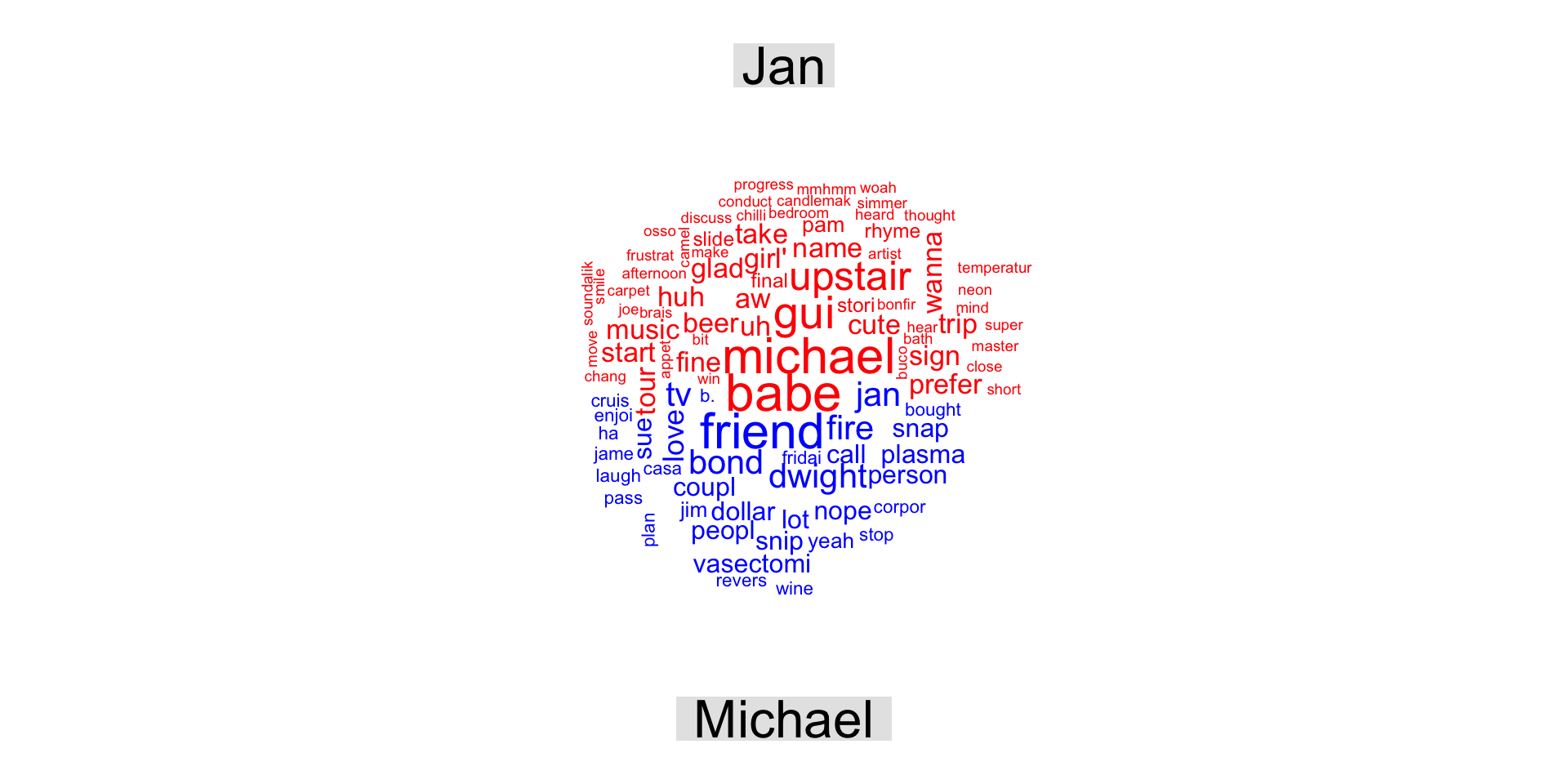
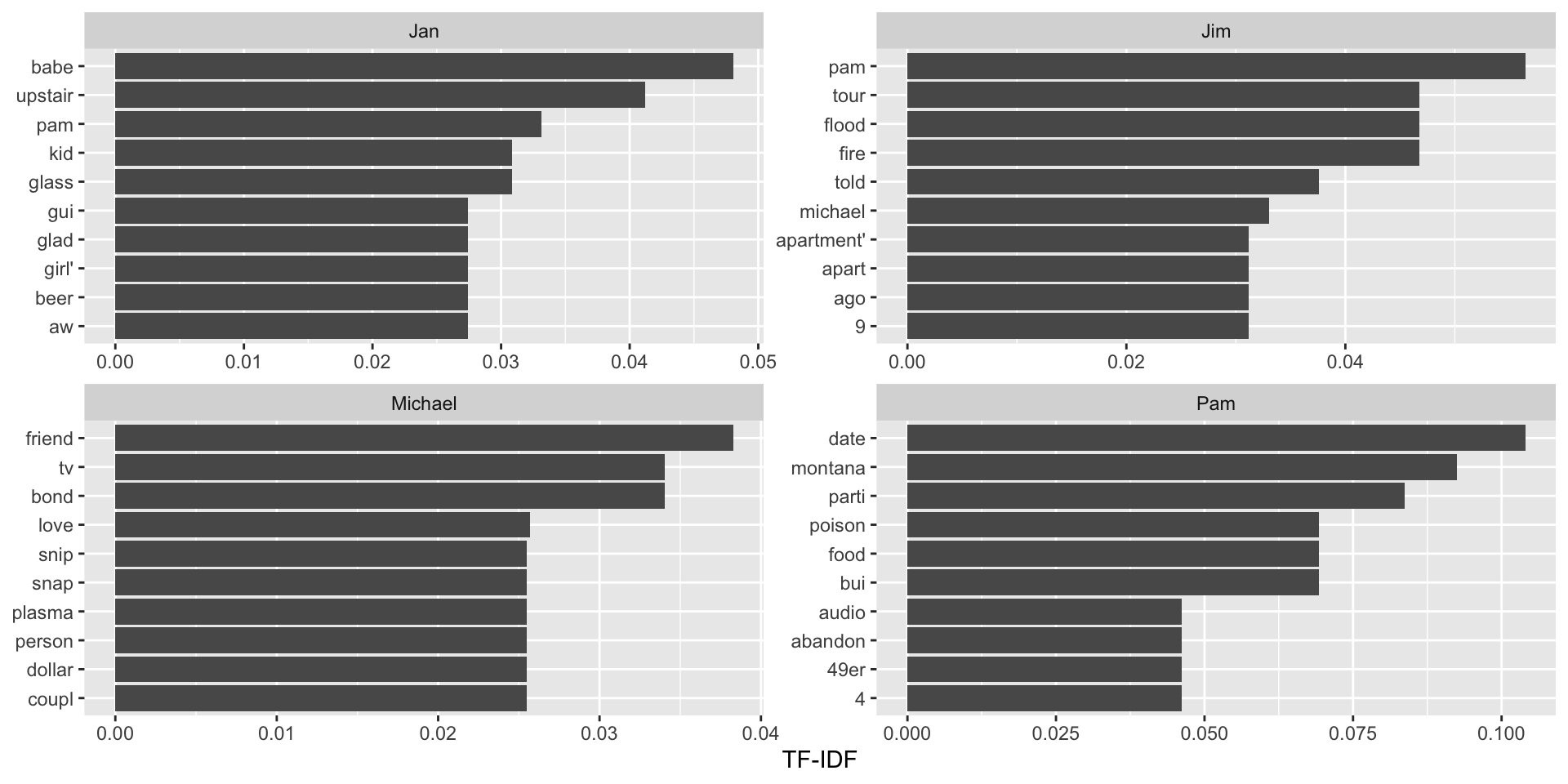
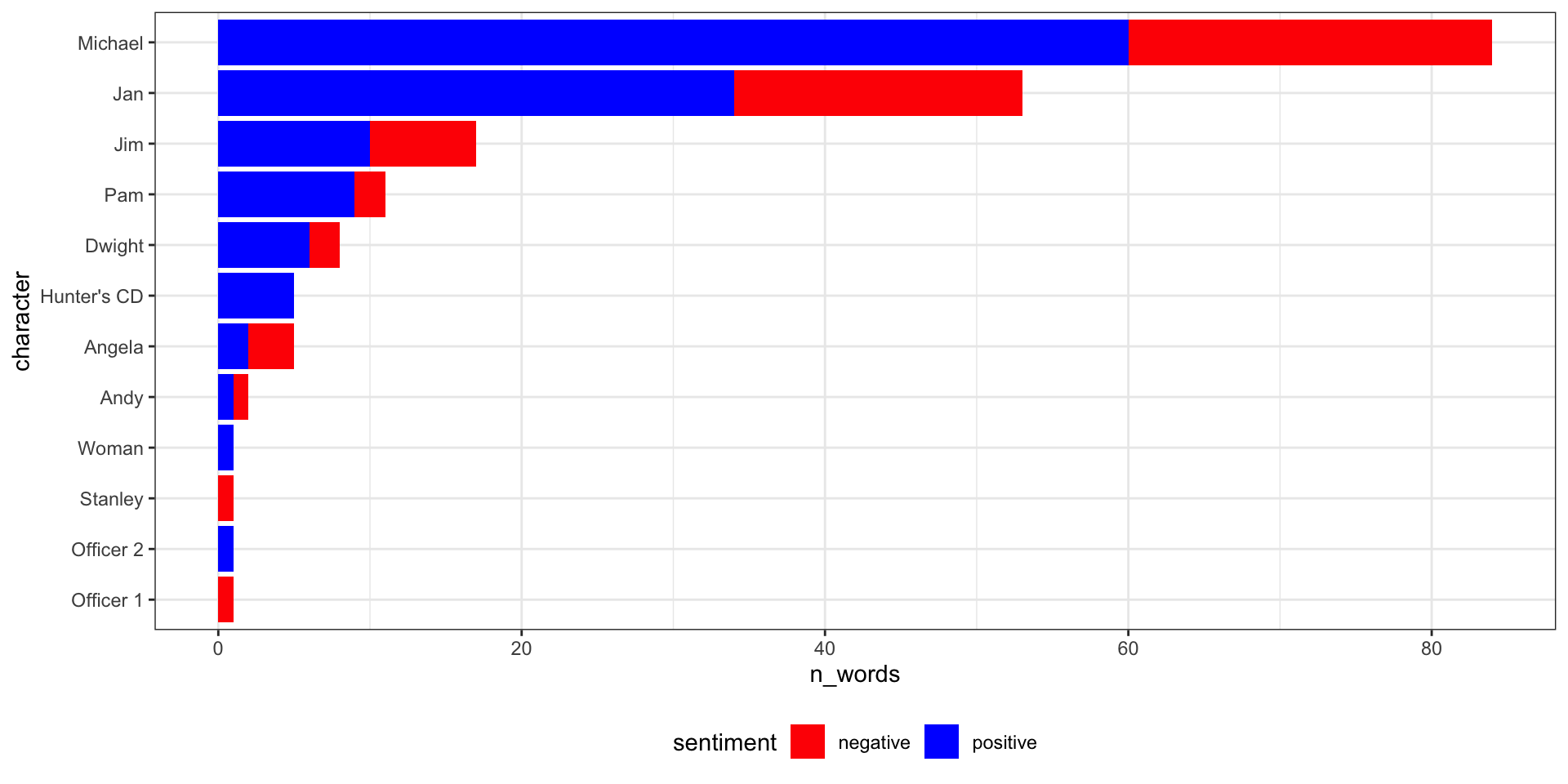
Bag of Words representation of text
- Most common way to store text data is with a document-term matrix (DTM):
| Document 1 |
\(w_{11}\) |
\(w_{12}\) |
\(\dots\) |
\(w_{1J}\) |
| Document 2 |
\(w_{21}\) |
\(w_{22}\) |
\(\dots\) |
\(w_{2J}\) |
| \(\dots\) |
\(\dots\) |
\(\dots\) |
\(\dots\) |
\(\dots\) |
| Document N |
\(w_{N1}\) |
\(w_{N2}\) |
\(\dots\) |
\(w_{NJ}\) |
- \(w_{ij}\): count of word \(j\) in document \(i\), aka term frequencies
Two additional ways to reduce number of columns:
Stop words: remove extremely common words (e.g., of, the, a)
Stemming: Reduce all words to their “stem”
- For example: Reducing = reduc. Reduce = reduc. Reduces = reduc.